

BASES MOLECULARES DE LA HERENCIA

Para terminar con el primer bloque "Bases moleculares de la herencia" de nuestro curso, abordaremos el tema de código genético (nuclear) y la traducción. Este tema así como todos los ya revisados en el bloque, resulta ser bastante práctico e interesante... Y claro tan importante como todos dentro del estudio del maravilloso mundo de la genética.
Una vez fabricado el ARNm, la información presente en su secuencia se utilizará para la síntesis de una proteína. La transcripción es un proceso fácil, dado que el ADN puede actuar de forma directa como un molde para la síntesis del ARN por apareamiento entre bases complementarias. Por el contrario, la conversión de la información del ARN a proteína representa una traducción con símbolos muy diferentes. Esta traducción no puede realizarse uno a uno entre los nucleótidos del ARNm y los aminoácidos de la proteína.
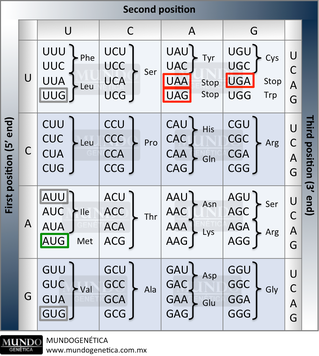
Figura 1. El código genético consiste en 64 codones y los aminoácidos especificados por estos codones. Los codones se escriben en dirección 5' -> 3', como aparecen en el ARNm. AUG es un codón de iniciación; UAA, UAG y UGA son codones de terminación.2
(Clic en imagen para ampliar).
La secuencia de nucleótidos de un RNAm se lee en grupos consecutivos de tres nucleótidos o tripletes. El ARN es un polímero de cuatro nucleótidos diferentes, así que hay 4x4x4=64 combinaciones posibles de tres nucleótidos que en consecución codifican un aminoácido o señal del proceso de la traducción.1 Tres son codones de terminación, mientras que 61 codones llamados codones con sentido codifican para los aminoácidos. Por lo tanto algunos aminoácidos son especificados por más de un triplete (codones sinónimos) por esto se dice que es un código degenerado. Solamente el triptófano y la metionina están codificados por un solo codón.2
Como siempre, ¡Tenemos algo para ti! Si el tema se te ha complicado puedes revisar este vídeo que hemos encontrado para ti.

Esperamos que después de este vídeo hayas logrado comprender lo que te hemos venido explicando... ¡Continuemos!
Características del código genético
A) El código es universal. Se observa la misma correspondencia en todos los sistemas estudiados. (Sólo en los sistemas de síntesis de proteínas de mitocondrias y algunos protozoos se han descubierto variaciones).
B) El código contiene un triplete de iniciación (AUG) correspondiente a metionina. La traducción inicia por este triplete y codifica el aminoácido mencionado.
C) El código contiene tres tripletes sin sentido (UAA, UAG y UGA) a los que no corresponde ningún aminoácido y sirven para finalizar la traducción.
D) El código contiene 61 tripletes para codificar 20 aminoácidos.
E) Los tripletes aparecen yuxtapuestos en el mensajero, desde iniciación a terminación sin huecos ni solapamientos. 3
Marco de lectura
Una secuencia de RNA podría traducirse siguiendo cualquiera de los marcos de lectura diferentes dependiendo del punto en que empiece el proceso de descodificación (Ver figura 2).

Figura 2. Ejemplo de marco de lectura (Clic en imagen para ampliar).
Los tres marcos de lectura tienen conjuntos distintos de codones que especificarán proteínas con secuencias distintas.1 Por lo que sólo una de las tres pautas de lectura de un ARNm codifica la proteína correcta.2 El marco de lectura queda establecido por el codón de iniciación.1
¡Vaya! Parece que hemos encontrado algo para ti..

|
Términos a utilizar Cadena molde Cadena codificante Subunidad ribosomal menor Subunidad ribosomal mayor Sitios A, P y E (del ribosoma) Codones de iniciación y terminación ARNt Codón Anticodón |
Imagen encontrada en el Libro: CURSOS CRASH: Lo esencial en la célula y genética.
Imagen encontrada en el Libro: CURSOS CRASH: Lo esencial en la célula y genética.

